最近在研究CPU的微内核,遇到了一个问题:为何CPU要求内存访问对齐?
换句话说:CPU访问非对齐的内存时为何需要多次读取再拼接?
首先简单说一下何为内存对齐。
例如,当cpu需要取4个连续的字节时,若内存起始位置的地址可以被4整除,那么我们称其对齐访问。
反之,则为未对齐访问。比如从地址0xf1取4字节就是非对齐(地址)访问。
简单的看来,对于一个数据总线宽度为32位的cpu,它一次拥有取出四字节数据的能力,理论上cpu应该是可以从任意的内存地址取四个连续字节的,而且是否对齐硬件的设计是相同的(如果内存和CPU都是字节组织的话,那么内存应当可以返回任意地址开始连续的四字节,CPU处理起来也没有任何差异)。
然而,很多cpu并不支持非对齐的内存访问,甚至在访问的时候会发生例外(例如arm架构的某些CPU)!而某些复杂指令集的cpu(比如x86架构),可以完成非对齐的内存访问,然而CPU也不是一次性读出四个字节,而是采取多次读取对齐的内存,然后进行数据拼接,从而实现非对齐数据访问的。如下图:
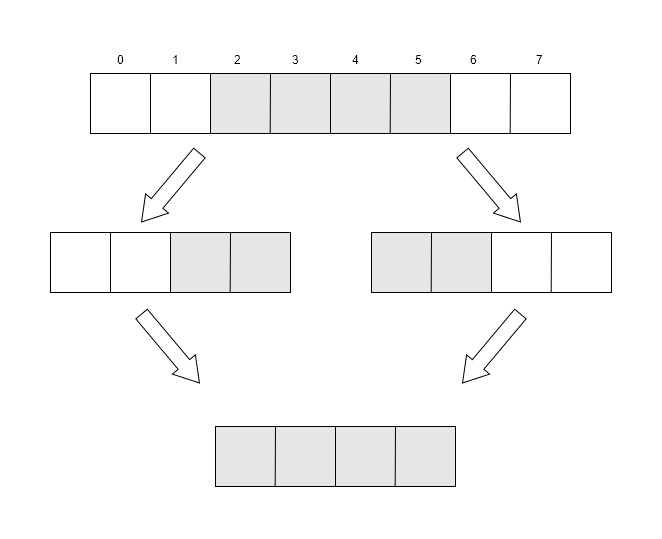
如果我们的数据存于内存的2-5中,在读取时实际上是先读取0-3,再读取4-7字节,再分别将2-3字节和4-5字节合并,最后得到所需的四字节数据。
那么为什么CPU不直接读取2-5,而是要么不提供支持,要么甚至不惜花大力气执行多次访问再拼接访问非对齐的内存呢(如此访问一则增加访问时间,二则增加电路的复杂性)?这背后一定有它的原因!
经过一番互联网搜索,但是在国内只能找到为什么写程序的时候要对齐的解释(因为CPU要么不支持,要么访问效率下降),然后是如何实现对齐。没有一篇文章从硬件原理上去分析为何访问非对齐内存如此麻烦。
最后我在神奇的StackOverflow网站上找到了相关的问题,以及合理的解答(看来并不是只有我一个人有类似的疑问)。
实际上,访问非对齐内存并没有我们想象的那么“简单”,例如,在一个常见的pc上,内存实际上是有多个内存芯片共同组成的(也就是内存条上那些黑色的内存颗粒)
为了提高访存的带宽,通常的做法是将地址分开,放到不同的芯片上,比如,第0-7bit在芯片0上储存,8-15bit在芯片2上组成,以此类推,如下图:
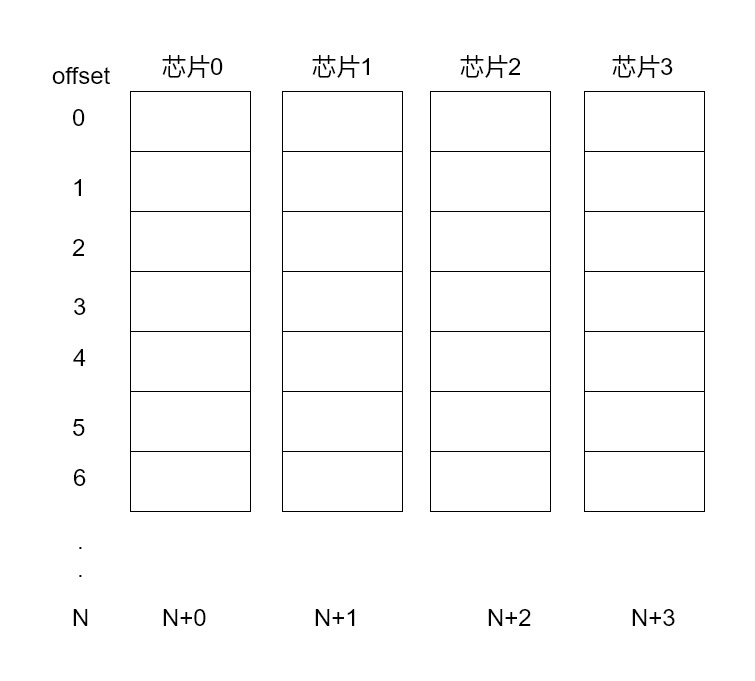
这意味内存实际上并不是完全以byte形式组织的,而是以偏移量(offset)来给出具体地址的。
这样当我们采用对齐的地址访问时,比如从0x00开始访问四字节,显然四个字节储存于4个芯片,而且他们都有同样的偏移量(offset),这时我们就能一次获得所需的数据。
但是当从0x01开始读取4字节呢?此时前三个字节也是按顺序分别储存在1-3芯片中的,而且偏移量都是0,但是第四个字节却储存在偏移量为1的芯片0中。
在访问内存时,CPU需要给出偏移量offset,而发送偏移量的总线宽度大约是40位(64bit环境下),通常这样的总线只有一个。
这意味着在一次内存访问周期内我们只能读取一个结果。
当然,要想一次读取两个offset的内容也不是不能实现,你可以增加用于发送地址的bus数量。对于一个64位的cpu,如果你希望在一个访问周期内读取未对齐的内存,你需要增加到8根总线。这意味着需要增加接近300个io。而通常cpu的管脚数量在700-2000之间,在这基础之上增加300将会是一个很大的改动。换句话说,就是会大大增加硬件的复杂程度。
同时,内存访问信号的频率是非常高的,增加的总线也会造成额外的噪声干扰。
当然,还有一种方法。由于非对齐访问最多也就访问两个不同的offset,而且这两个offset总是连续,我们可以再给内存内部加一根额外的线,这样就可以同时返回offset和offset+1两个偏移量上的数据了。
但是,这样意味着芯片内多了一些额外的加法器(用于给offset加一,得到下一个偏移量),所有的读操作都会在读取前增加一个计算操作。
这一步会降低内存的时钟。于是乎,我们可能为了千分之一概率出现的非对齐访问,增加了99.9%的对齐访问的访问延时。显然这并不是一个明智的选择。
因此,CPU不支持,或者通过两次读取来实现非对齐访问也就有理有据了。
当然,访问非对齐的数据还存在一个问题:cache
通常来说,cache是和offset相关联的,不同的offset被不同的cache line缓存,因此,访问非对齐的数据也意味着多次的cache读取,同样会降低效率。
综上所述,这些也基本上是访问非对齐内存需要多次读取的原因了。
参考资料:https://stackoverflow.com/questions/3903164/why-misaligned-address-access-incur-2-or-more-accesses
写得太好了
对, 楼上说的好. 写得太好了!
确实,楼上说得太好了!
Pingback: void* memcpy(void* src, void* dest, size_t len)转载
Pingback: memcpy()函数实现 | 高性能架构探索
Pingback: 实现memcpy()函数及过程总结 | 高性能架构探索
Pingback: 内存对齐_Johngo学长
楼上说的太对了
写的太好了
楼上们说的太对了